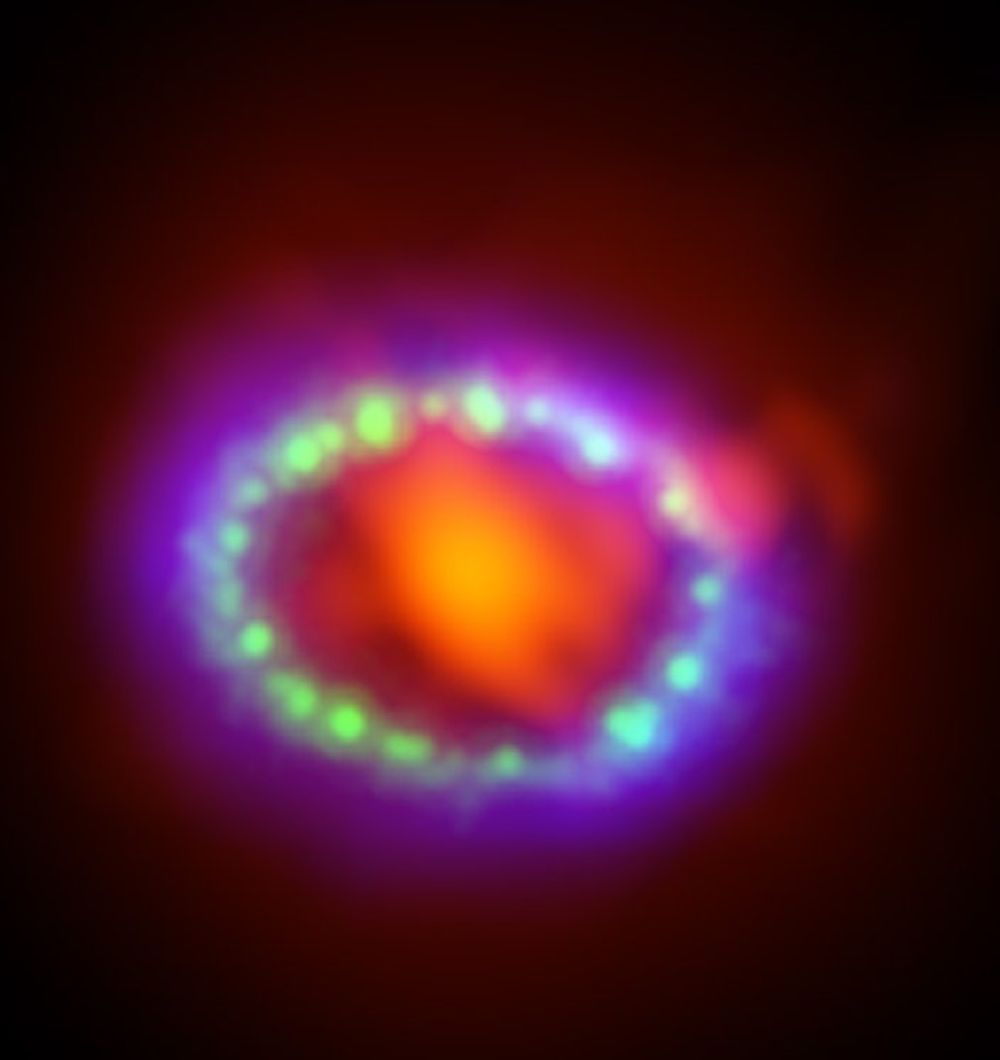
Illustration of a Type Ia supernova. Credit: Kiso Observatory, The University of Tokyo
Lots of things out in the Universe can cause a supernova, from the gravitational collapse of a massive star, to the collision of white dwarfs. But most of the supernovae we observe are in other galaxies, too distant for us to see the details of the process. So, instead, we categorize supernovae by observed characteristics such as the light curves of how they brighten and fade and the types of elements identified in their spectra. While this gives us some idea of the underlying cause, there are still things we don’t entirely understand. This is particularly true for one particular kind of supernova known as Type Ia.
The Hubble Space Telescope is amazing! It's still going strong more than 34 years after it was launched. This Hubble image showcases a nearly edge-on view of the lenticular galaxy NGC 4753.
ESA/Hubble & NASA, L. Kelsey
The world was much different in 1990 when NASA astronauts removed the Hubble Space Telescope from Space Shuttle Discovery’s cargo bay and placed it into orbit. The Cold War was ending, there were only 5.3 billion humans, and the World Wide Web had just come online.
NASA’s James Webb Space Telescope has spotted a multiply-imaged supernova in a distant galaxy designated MRG-M0138. Image Credit: NASA, ESA, CSA, STScI, Justin Pierel (STScI) and Andrew Newman (Carnegie Institution for Science).
Nature, in its infinite inventiveness, provides natural astronomical lenses that allow us to see objects beyond the normal reach of our telescopes. They’re called gravitational lenses, and a few years ago, the Hubble Space Telescope took advantage of one of them to spot a supernova explosion in a distant galaxy.
Now, the JWST has taken advantage of the same lens and found another supernova in the same galaxy.
Artist view of a binary system before a type Ia supernova. Credit: Adam Makarenko/W. M. Keck Observatory
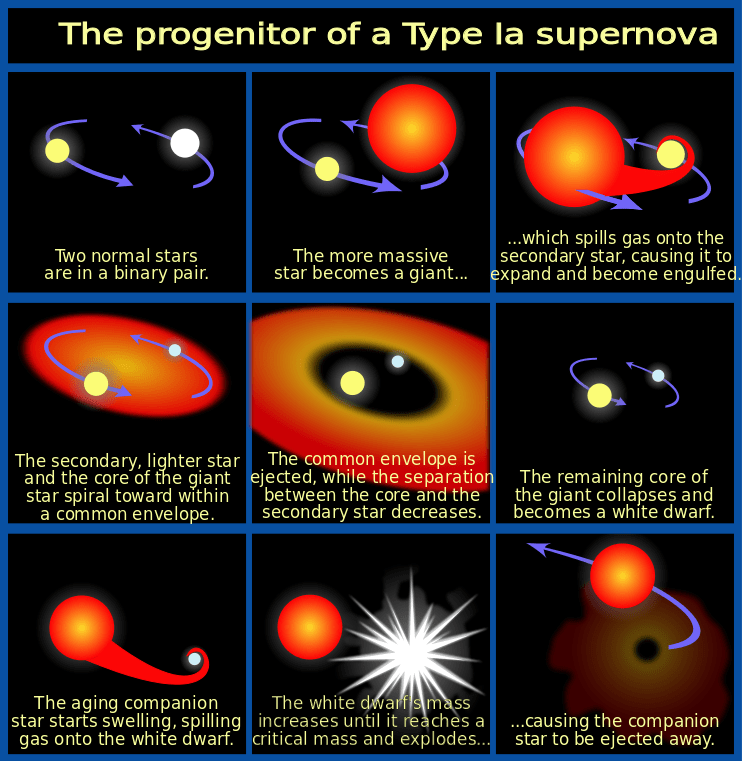
All supernovae are exploding stars. But the nature of a supernova explosion varies quite a bit. One type, named Type 1a supernovae, involves a binary star where one of the pair is a white dwarf. And while supernovae of all types usually involve a single explosion, astronomers have found something that breaks that mould: A Type 1a supernova that may have detonated twice.
The Hubble space telescope has provided some of the most spectacular astronomical pictures ever taken. Some of them have even been used to confirm the value of another Hubble – the constant that determines the speed of expansion of the Universe. Now, in what Nobel laureate Adam Reiss calls Hubble’s “magnum opus,” scientists have released a series of spectacular spiral galaxies that have helped pinpoint that expansion constant – and it’s not what they expected.
A composite image of SN 1987A from Hubble, Chandra, and ALMA. Image Credit: By ALMA (ESO/NAOJ/NRAO)/A. Angelich. Visible light image: the NASA/ESA Hubble Space Telescope. X-Ray image: The NASA Chandra X-Ray Observatory - http://www.eso.org/public/images/eso1401a/, CC BY 4.0, https://commons.wikimedia.org/w/index.php?curid=30512379
Neutrinos are puzzling things. They’re tiny particles, almost massless, with no electrical charge. They’re notoriously difficult to detect, too, and scientists have gone to great lengths to detect them. The IceCube Neutrino Observatory, for instance, tries to detect neutrinos with strings of detectors buried down to a depth of 2450 meters (8000 ft.) in the dark Antarctic ice.
A classical novae contains a white dwarf, and a larger companion star in orbit around it. The white dwarf attracts gas from its companion, leading to a massive explosion. Illustration Credit: David Hardy
The Big Bang produced the Universe’s hydrogen, helium, and a little lithium. Since then, it’s been up to stars (for the most part) to forge the rest of the elements, including the matter that you and I are made of. Stars are the nuclear forges responsible for creating most of the elements. But when it comes to lithium, there’s some uncertainty.
A new study shows where much of the lithium in our Solar System and our galaxy comes from: a type of stellar explosion called classical novae.
An artist's image of a white dwarf drawing material away from its companion. Image Credit: NASA
The star V Sagittae is the next candidate to explode in stellar pyrotechnics, and a team of astronomers set the year for that cataclysmic explosion at 2083, or thereabouts. V Sagittae is in the constellation Sagitta (latin for arrow,) a dim and barely discernible constellation in the northern sky. V Sagittae is about 1100 light years from Earth.
A supernova (bright spot at lower left) and its host galaxy (upper center), as they would appear if gravitationally lensed by an intervening black hole (center). Credit: Miguel Zumalacárregui/UC Berkeley
In February of 2016, scientists working for the Laser Interferometer Gravitational-Wave Observatory (LIGO) made history when they announced the first-ever detection of gravitational waves. Since that time, multiple detections have taken place and scientific collaborations between observatories – like Advanced LIGO and Advanced Virgo – are allowing for unprecedented levels of sensitivity and data sharing.
This event not only confirmed a century-old prediction made by Einstein’s Theory of General Relativity, it also led to a revolution in astronomy. It also stoked the hopes of some scientists who believed that black holes could account for the Universe’s “missing mass”. Unfortunately, a new study by a team of UC Berkeley physicists has shown that black holes are not the long-sought-after source of Dark Matter.
The Victor M. Blanco telescope at Cerro Tololo Interamerican Observatory (CTIO) in the Chilean Andes. Credit: Berkeley Lab
Since the early 20th century, scientists and physicists have been burdened with explaining how and why the Universe appears to be expanding at an accelerating rate. For decades, the most widely accepted explanation is that the cosmos is permeated by a mysterious force known as “dark energy”. In addition to being responsible for cosmic acceleration, this energy is also thought to comprise 68.3% of the universe’s non-visible mass.
Much like dark matter, the existence of this invisible force is based on observable phenomena and because it happens to fit with our current models of cosmology, and not direct evidence. Instead, scientists must rely on indirect observations, watching how fast cosmic objects (specifically Type Ia supernovae) recede from us as the universe expands.
This process would be extremely tedious for scientists – like those who work for the Dark Energy Survey (DES) – were it not for the new algorithms developed collaboratively by researchers at Lawrence Berkeley National Laboratory and UC Berkeley.
“Our algorithm can classify a detection of a supernova candidate in about 0.01 seconds, whereas an experienced human scanner can take several seconds,” said Danny Goldstein, a UC Berkeley graduate student who developed the code to automate the process of supernova discovery on DES images.
Currently in its second season, the DES takes nightly pictures of the Southern Sky with DECam – a 570-megapixel camera that is mounted on the Victor M. Blanco telescope at Cerro Tololo Interamerican Observatory (CTIO) in the Chilean Andes. Every night, the camera generates between 100 Gigabytes (GB) and 1 Terabyte (TB) of imaging data, which is sent to the National Center for Supercomputing Applications (NCSA) and DOE’s Fermilab in Illinois for initial processing and archiving.
By studying Type Ia supernova, astronomers can measure dark energy and the expansion of the universe. Credit: NASA/CXC/M. Weiss
Object recognition programs developed at the National Energy Research Scientific Computing Center (NERSC) and implemented at NCSA then comb through the images in search of possible detections of Type Ia supernovae. These powerful explosions occur in binary star systems where one star is a white dwarf, which accretes material from a companion star until it reaches a critical mass and explodes in a Type Ia supernova.
“These explosions are remarkable because they can be used as cosmic distance indicators to within 3-10 percent accuracy,” says Goldstein.
Distance is important because the further away an object is located in space, the further back in time it is. By tracking Type Ia supernovae at different distances, researchers can measure cosmic expansion throughout the universe’s history. This allows them to put constraints on how fast the universe is expanding and maybe even provide other clues about the nature of dark energy.
“Scientifically, it’s a really exciting time because several groups around the world are trying to precisely measure Type Ia supernovae in order to constrain and understand the dark energy that is driving the accelerated expansion of the universe,” says Goldstein, who is also a student researcher in Berkeley Lab’s Computational Cosmology Center (C3).
Goldstein’s new code uses machine learning techniques to vet detections of supernova candidates. Credit: Danny Goldstein, UC Berkeley/Berkeley Lab)
The DES begins its search for Type Ia explosions by uncovering changes in the night sky, which is where the image subtraction pipeline developed and implemented by researchers in the DES supernova working group comes in. The pipeline subtracts images that contain known cosmic objects from new images that are exposed nightly at CTIO.
Each night, the pipeline produces between 10,000 and a few hundred thousand detections of supernova candidates that need to be validated.
“Historically, trained astronomers would sit at the computer for hours, look at these dots, and offer opinions about whether they had the characteristics of a supernova, or whether they were caused by spurious effects that masquerade as supernovae in the data. This process seems straightforward until you realize that the number of candidates that need to be classified each night is prohibitively large and only one in a few hundred is a real supernova of any type,” says Goldstein. “This process is extremely tedious and time-intensive. It also puts a lot of pressure on the supernova working group to process and scan data fast, which is hard work.”
To simplify the task of vetting candidates, Goldstein developed a code that uses the machine learning technique “Random Forest” to vet detections of supernova candidates automatically and in real-time to optimize them for the DES. The technique employs an ensemble of decision trees to automatically ask the types of questions that astronomers would typically consider when classifying supernova candidates.
Evolution of a Type Ia supernova. Credit: NASA/ESA/A. Feild
At the end of the process, each detection of a candidate is given a score based on the fraction of decision trees that considered it to have the characteristics of a detection of a supernova. The closer the classification score is to one, the stronger the candidate. Goldstein notes that in preliminary tests, the classification pipeline achieved 96 percent overall accuracy.
“When you do subtraction alone you get far too many ‘false-positives’ — instrumental or software artifacts that show up as potential supernova candidates — for humans to sift through,” says Rollin Thomas, of Berkeley Lab’s C3, who was Goldstein’s collaborator.
He notes that with the classifier, researchers can quickly and accurately strain out the artifacts from supernova candidates. “This means that instead of having 20 scientists from the supernova working group continually sift through thousands of candidates every night, you can just appoint one person to look at maybe few hundred strong candidates,” says Thomas. “This significantly speeds up our workflow and allows us to identify supernovae in real-time, which is crucial for conducting follow up observations.”
“Using about 60 cores on a supercomputer we can classify 200,000 detections in about 20 minutes, including time for database interaction and feature extraction.” says Goldstein.
Goldstein and Thomas note that the next step in this work is to add a second-level of machine learning to the pipeline to improve the classification accuracy. This extra layer would take into account how the object was classified in previous observations as it determines the probability that the candidate is “real.” The researchers and their colleagues are currently working on different approaches to achieve this capability.