Illustration of an active quasar. New research shows that SMBHs eat rapidly enough to trigger them. Credit: ESO/M. Kornmesser
At the heart of large galaxies like our Milky Way, there resides a supermassive black hole (SMBH.) These behemoths draw stars, gas, and dust toward them with their irresistible gravitational pull. When they consume this material, there’s a bright flare of energy, the brightest of which are quasars.
While astrophysicists think that SMBHs eat too slowly to cause a particular type of quasar, new research suggests otherwise.
Computer simulation of magnetic structures in solar-like conditions. Image: Jörn Warnecke
It’s almost impossible to over-emphasize the primal, raging, natural power of a star. Our Sun may appear benign in simple observations, but with the advanced scientific instruments at our disposal in modern times, we know differently. In observations outside the narrow band of light our eyes can see, the Sun appears as an enraged, infuriated sphere, occasionally hurling huge jets of plasma into space, some of which slam into Earth.
Jets of plasma slamming into Earth isn’t something to be celebrated (unless you’re in a weird cult); it can cause all kinds of problems.
In all of scientific modeling, the models attempting to replicate planetary and solar system formation are some of the most complicated. They are also notoriously difficult to develop. Normally they center around one of two formative ideas: planets are shaped primarily by gravity or planets are shaped primarily by magnetism. Now a new theoretical model has been developed by a team at the University of Zurich (UZH) that uses math from both methodologies to inform the most complete model yet of planetary formation.
The figure shows a section through the cube of the turbulence simulation. The colors show the density contrast relative to the mean density of the gas. Its turbulent structure is clearly recognizable. Image Credit: Federrath et al, 2021.
How do stars form?
We know they form from massive structures called molecular clouds, which themselves form from the Interstellar Medium (ISM). But how and why do certain types of stars form? Why, in some situations, does a star like our Sun form, versus a red dwarf or a blue giant?
That’s one of the central questions in astronomy. It’s also a very complex one.
Early stars were made solely of hydrogen and helium. Credit: NASA/WMAP Science Team
For astronomers, astrophysicists, and cosmologists, the ability to spot the first stars that formed in our Universe has always been just beyond reach. On the one hand, there are the limits of our current telescopes and observatories, which can only see so far. The farthest object ever observed was MACS 1149-JD, a galaxy located 13.2 billion light-years from Earth that was spotted in the Hubble eXtreme Deep Field (XDF) image.
On the other, up until about 1 billion years after the Big Bang, the Universe was experiencing what cosmologists refer to as the “Dark Ages” when the Universe was filled with gas clouds that obscured visible and infrared light. Luckily, a team of researchers from Georgia Tech’s Center for Relativistic Astrophysics recently conducted simulations that show what the formation of the first stars looked like.
A 2-D snapshot of a pair-instability supernovae as the explosion waves are about to break through the star's surface. The tiny disturbances represent fluid instability - in a region where different elements interact and mix. Image Credit: ASIAA/Ken Chen
The answers to many questions in astronomy are hidden behind the veil of deep time. One of those questions is around the role that supernovae played in the early Universe. It was the job of early supernovae to forge the heavier elements that were not forged in the Big Bang. How did that process play out? How did those early stellar explosions play out?
A trio of researchers turned to a supercomputer simulation to find some answers.
The all-sky view that the Gaia survey would have of a simulated Milky-Way-like galaxy. [Credit: Sanderson et al. The Astrophysical Journal, January 6, 2020, DOI: 10.3847/1538-4365/ab5b9d]
Modern professional astronomers aren’t much like astronomers of old. They don’t spend every suitable evening with their eyes glued to a telescope’s eyepiece. You might be more likely to find them in front of a super-computer, working with AI and deep learning methods.
One group of researchers employed those methods to find a whole new collection of stars in the Milky Way; a group of stars which weren’t born here.
Where do they come from, those beguiling singularities that flummox astrophysicists—and the rest of us. Sure, we understand the processes behind stellar mass black holes, and how they form from the gravitational collapse of a star.
But what about the staggering behemoths at the center of galaxies, those supermassive black holes (SMBH) that can grow to be billions of times more massive than our Sun?
Artist’s impression of the full Square Kilometre Array at night. Credit: SKA Organisation
When complete, the Square Kilometer Array (SKA) will be the largest radio telescope array in the entire world. The result of decades of work involving 40 institutions in 11 countries, the SKA will allow astronomers to monitor the sky in unprecedented detail and survey it much faster than with any system currently in existence.
Such a large array will naturally be responsible for gathering an unprecedented amount of data on a regular basis. To sort through all this data, the “brain” for this massive array will consist of two supercomputers. Recently, the SKA’s Science Data Processor (SDP) consortium concluded their engineering design work on one of these supercomputers.
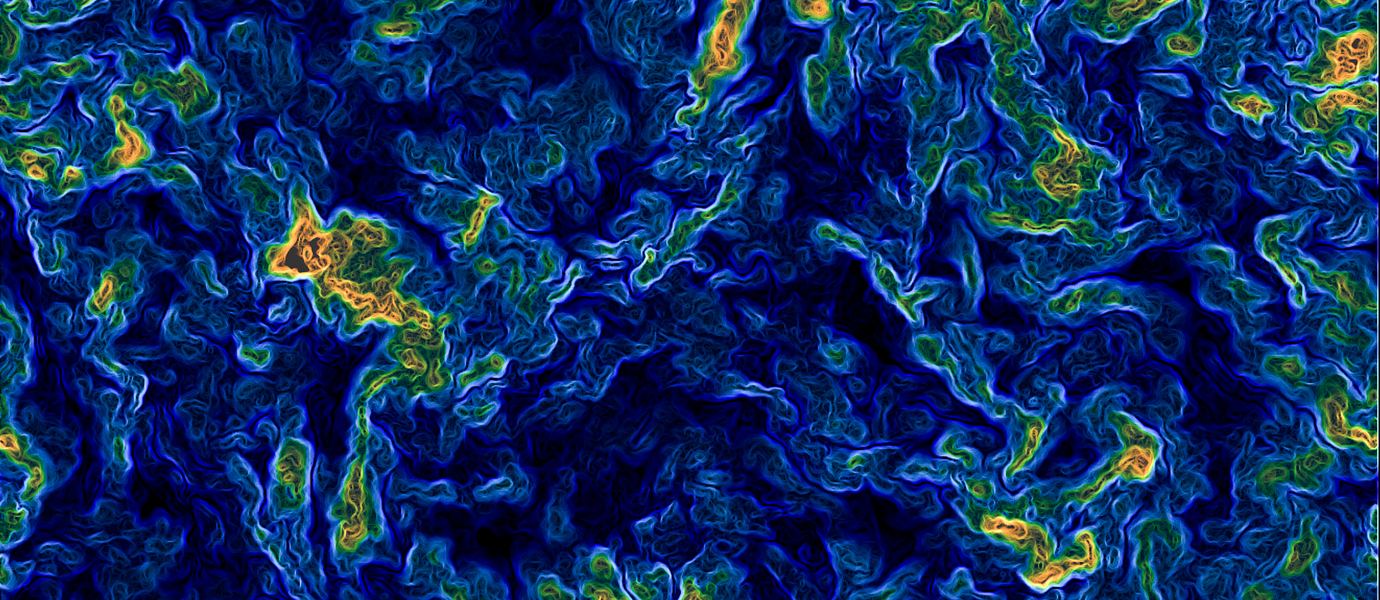
Composite which combines gas temperature (as the color) and shock mach number (as the brightness). Red indicates 10 million Kelvin gas at the centers of massive galaxy clusters, while bright structures show diffuse gas from the intergalactic medium shock heating at the boundary between cosmic voids and filaments. Credit: Illustris Team
Since time immemorial, philosophers and scholars have sought to determine how existence began. With the birth of modern astronomy, this tradition has continued and given rise to the field known as cosmology. And with the help of supercomputing, scientists are able to conduct simulations that show how the first stars and galaxies formed in our Universe and evolved over the course of billions of years.
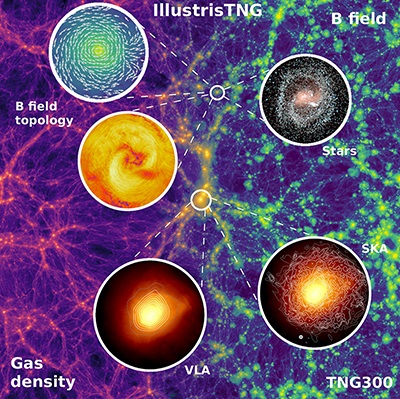
Until recently, the most extensive and complete study was the “Illustrus” simulation, which looked at the process of galaxy formation over the course of the past 13 billion years. Seeking to break their own record, the same team recently began conducting a simulation known as “Illustris, The Next Generation,” or “IllustrisTNG”. The first round of these findings were recently released, and several more are expected to follow.
This illustration shows the evolution of the Universe, from the Big Bang on the left, to modern times on the right. Image: NASA
Using the Hazel Hen supercomputer at the High-Performance Computing Center Stuttgart (HLRS) – one of the three world-class German supercomputing facilities that comprise the Gauss Centre for Supercomputing (GCS) – the team conducted a simulation that will help to verify and expand on existing experimental knowledge about the earliest stages of the Universe – i.e. what happened from 300,000 years after the Big Bang to the present day.
To create this simulation, the team combined equations (such as the Theory of General Relativity) and data from modern observations into a massive computational cube that represented a large cross-section of the Universe. For some processes, such as star formation and the growth of black holes, the researchers were forced to rely on assumptions based on observations. They then employed numerical models to set this simulated Universe in motion.
Compared to their previous simulation, IllustrisTNG consisted of 3 different universes at three different resolutions – the largest of which measured 1 billion light years (300 megaparsecs) across. In addition, the research team included more precise accounting for magnetic fields, thus improving accuracy. In total, the simulation used 24,000 cores on the Hazel Hen supercomputer for a total of 35 million core hours.
As Prof. Dr. Volker Springel, professor and researcher at the Heidelberg Institute for Theoretical Studies and principal investigator on the project, explained in a Gauss Center press release:
“Magnetic fields are interesting for a variety of reasons. The magnetic pressure exerted on cosmic gas can occasionally be equal to thermal (temperature) pressure, meaning that if you neglect this, you will miss these effects and ultimately compromise your results.”
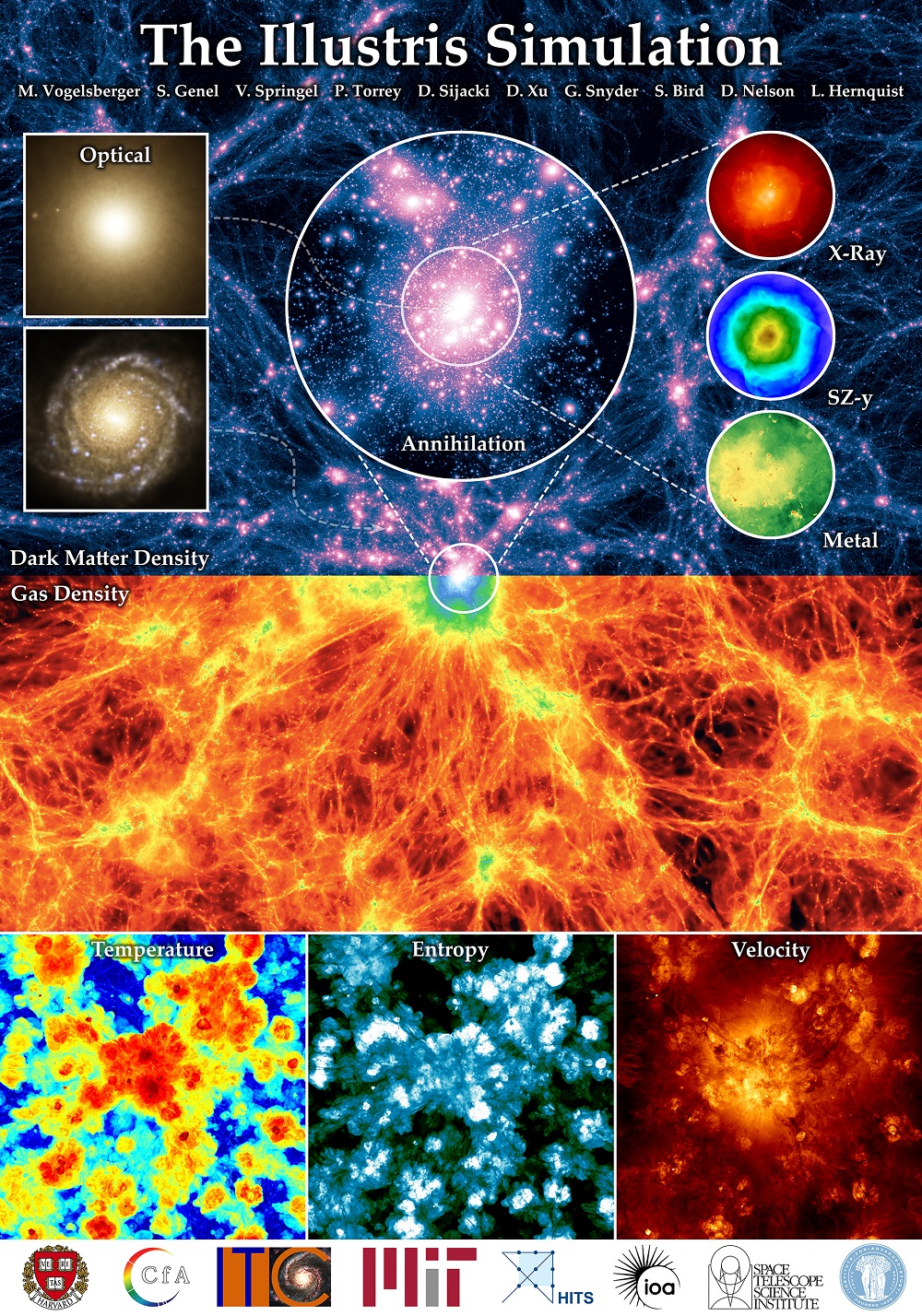
Illustris simulation overview poster. Shows the large scale dark matter and gas density fields in projection (top/bottom). Credit: Illustris Project
Another major difference was the inclusion of updated black hole physics based on recent observation campaigns. This includes evidence that demonstrates a correlation between supermassive black holes (SMBHs) and galactic evolution. In essence, SMBHs are known to send out a tremendous amount of energy in the form of radiation and particle jets, which can have an arresting effect on star formation in a galaxy.
While the researchers were certainly aware of this process during the first simulation, they did not factor in how it can arrest star formation completely. By including updated data on both magnetic fields and black hole physics in the simulation, the team saw a greater correlation between the data and observations. They are therefore more confident with the results and believe it represents the most accurate simulation to date.
But as Dr. Dylan Nelson – a physicist with the Max Planck Institute of Astronomy and an llustricTNG member – explained, future simulations are likely to be even more accurate, assuming advances in supercomputers continue:
“Increased memory and processing resources in next-generation systems will allow us to simulate large volumes of the universe with higher resolution. Large volumes are important for cosmology, understanding the large-scale structure of the universe, and making firm predictions for the next generation of large observational projects. High resolution is important for improving our physical models of the processes going on inside of individual galaxies in our simulation.”
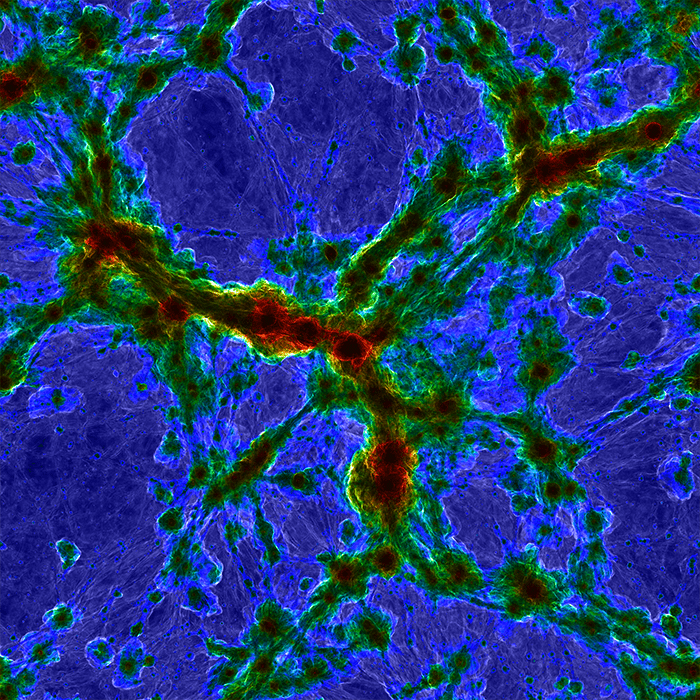
Gas density (left) and magnetic field strength (right) centered on the most massive galaxy cluster. Credit: Illustris Team
This latest simulation was also made possible thanks to extensive support provided by the GCS staff, who assisted the research team with matters related to their coding. It was also the result of a massive collaborative effort that brought together researchers from around the world and paired them with the resources they needed. Last, but not least, it shows how increased collaboration between applied research and theoretical research lead to better results.
Looking ahead, the team hopes that the results of this latest simulation proves to be even more useful than the last. The original Illustris data release gained over 2,000 registered users and resulted in the publication of 130 scientific studies. Given that this one is more accurate and up-to-date, the team expects that it will find more users and result in even more groundbreaking research.
Who knows? Perhaps someday, we may create a simulation that captures the formation and evolution of our Universe with complete accuracy. In the meantime, be sure to enjoy this video of the first Illustris Simulation, courtesy of team member and MIT physicist Mark Vogelsberger: