The Karl Jansky Very Large Array at night, with the Milky Way visible in the sky. Credit: NRAO/AUI/NSF; J. Hellerman
In July of 2015, Breakthrough Initiatives announced that it was embarking on a ten-year initiative to conduct the largest Search for Extraterrestrial Intelligence (SETI) to date. This initiative was aptly named Breakthrough Listen, which combines state-of-the-art software and data obtained by premier observatories around the world to look for signs of extraterrestrial technological activity (aka. technosignatures).
In recent years, Breakthrough Listen has made two majorreleases of data, and announced a lucrative collaboration with NASA’s Transitting Exoplanet Survey Satellite (TESS) mission. And most recently, Breakthrough Listen announced the release of their catalog of “Exotica” – a diverse list of objects that could be of interest to astronomers that are searching for signs of technosignatures and extraterrestrial intelligence (ETI).
A home PC running SETI at Home helping to churn through observational data Credit: SETI@home
In May of 1999, the Berkeley SETI Research Center launched a citizen-science program that would make the Search for Extra-Terrestrial Intelligence (SETI) open to the public. The brainchild of computer scientist David Gedye, this program would rely on large numbers of internet-connected computers to sort through the volumes of data collected by institutions participating in SETI efforts.
The program was appropriately named SETI@home and would rely on the computers of volunteers to process radio signals for signs of transmissions. And after twenty years, the program recently announced that it has gone into hibernation. The reason, they claim, is that the program’s network has become too big for its own britches and the scientists behind it need time to process and share all the results they’ve obtained so far.
Stardust in the Perseus Molecular Cloud, a star-forming region in the Perseus constellation. Credit & Copyright: Lorand Fenyes
For us Earthlings, life under a single Sun is just the way it is. But with the development of modern astronomy, we’ve become aware of the fact that the Universe is filled with binary and even triple star systems. Hence, if life does exist on planets beyond our Solar System, much of it could be accustomed to growing up under two or even three suns. For centuries, astronomers have wondered why this difference exists and how star systems came to be.
Whereas some astronomers argue that individual stars formed and acquired companions over time, others have suggested that systems began with multiple stars and lost their companions over time. According to a new study by a team from UC Berkeley and the Harvard-Smithsonian Center for Astrophysics (CfA), it appears that the Solar System (and other Sun-like stars) may have started out as binary system billions of years ago.
This study, titled “Embedded Binaries and Their Dense Cores“, was recently accepted for publication in the Monthly Notices of the Royal Astronomical Society. In it, Sarah I. Sadavoy – a radio astronomer from the Max Planck Institute for Astronomy and the CfA – and Steven W. Stahler (a theoretical physicist from UC Berkeley) explain how a radio surveys of a star nursery led them to conclude that most Sun-like stars began as binaries.
The dark molecular cloud, Barnard 68, is a stellar nursery that can only be studied using radio astronomy. Credit: FORS Team, 8.2-meter VLT Antu, ESO
For several decades, astronomers have known that stars are born inside “stellar nurseries”, which are the dense cores that exist within immense clouds of dust and cold, molecular hydrogen. These clouds look like holes in the star field when viewed through an optical telescope, thanks to all the dust grains that obscure light coming from the stars forming within them and from background stars.
Radio surveys are the only way to probe these star-forming regions, since the dust grains emit radio transmissions and also do not block them. For years, Stahler has been attempting to get radio astronomers to examine molecular clouds in the hope of gathering information on the formation of young stars inside them. To this end, he approached Sarah Sadavoy – a member of the VANDAM team – and proposed a collaboration.
The two began their work together by conducting new observations of both single and binary stars within the dense core regions of the Perseus cloud. As Sadavoy explained in a Berkeley News press release, the duo were looking for clues as to whether young stars formed as individuals or in pairs:
“The idea that many stars form with a companion has been suggested before, but the question is: how many? Based on our simple model, we say that nearly all stars form with a companion. The Perseus cloud is generally considered a typical low-mass star-forming region, but our model needs to be checked in other clouds.”
Infrared image from the Hubble Space Telescope, showing a bright, fan-shaped object (lower right quadrant) thought to be a binary star that emits light pulses as the two stars interact. Credit: NASA/ESA/ J. Muzerolle (STScI)
Their observations of the Perseus cloud revealed a series of Class 0 and Class I stars – those that are <500,000 old and 500,000 to 1 million years old, respectively – that were surrounded by egg-shaped cocoons. These observations were then combined with the results from VANDAM and other surveys of star forming regions – including the Gould Belt Survey and data gathered by SCUBA-2 instrument on the James Clerk Maxwell Telescope in Hawaii.
From this, they created a census of stars within the Perseus cloud, which included 55 young stars in 24 multiple-star systems (all but five of them binary) and 45 single-star systems. What they observed was that all of the widely separated binary systems – separated by more than 500 AU – were very young systems containing two Class 0 stars that tended to be aligned with the long axis of their egg-shaped dense cores.
Meanwhile, the slightly older Class I binary stars were closer together (separated by about 200 AU) and did not have the same tendency as far as their alignment was concerned. From this, the study’s authors began mathematically modelling multiple scenarios to explain this distribution, and concluded that all stars with masses comparable to our Sun start off as wide Class 0 binaries. They further concluded that 60% of these split up over time while the rest shrink to form tight binaries.
“As the egg contracts, the densest part of the egg will be toward the middle, and that forms two concentrations of density along the middle axis,” said Stahler. “These centers of higher density at some point collapse in on themselves because of their self-gravity to form Class 0 stars. “Within our picture, single low-mass, sunlike stars are not primordial. They are the result of the breakup of binaries. ”
The two brightest stars of the Centaurus constellation, the binary star system of Alpha Centauri. Credit: Wikipedia Commons/Skatebiker
Findings of this nature have never before been seen or tested. They also imply that each dense core within a stellar nursery (i.e. the egg-shaped cocoons, which typically comprise a few solar masses) converts twice as much material into stars as was previously thought. As Stahler remarked:
“The key here is that no one looked before in a systematic way at the relation of real young stars to the clouds that spawn them. Our work is a step forward in understanding both how binaries form and also the role that binaries play in early stellar evolution. We now believe that most stars, which are quite similar to our own sun, form as binaries. I think we have the strongest evidence to date for such an assertion.”
This new data could also be the start of a new trend, where astronomers rely on radio telescopes to examine dense star-forming regions with the hopes of witnessing more in the way of stellar formations. With the recent upgrades to the VLA and the Atacama Large Millimeter/submillimeter Array (ALMA) in Chile, and the ongoing data provided by the SCUBA-2 survey in Hawaii, these studies may be coming sooner other than later.
Another interesting implication of the study has to do with something known as the “Nemesis hypothesis”. In the past, astronomers have conjectured that a companion star named “Nemesis” existed within our Solar System. This star was so-named because the theory held that it was responsible for kicking the asteroid which caused the extinction of the dinosaurs into Earth’s orbit. Alas, all attempts to find Nemesis ended in failure.
Artist’s impression of the binary star system of Sirius, a white dwarf star in orbit around Sirius (a white supergiant). Credit: NASA, ESA and G. Bacon (STScI)
As Steven Stahler indicated, these findings could be interpreted as a new take on the Nemesis theory:
“We are saying, yes, there probably was a Nemesis, a long time ago. We ran a series of statistical models to see if we could account for the relative populations of young single stars and binaries of all separations in the Perseus molecular cloud, and the only model that could reproduce the data was one in which all stars form initially as wide binaries. These systems then either shrink or break apart within a million years.”
So while their results do not point towards a star being around for the extinction of the dinosaurs, it is possible (and even highly plausible) that billions of years ago, the Solar planets orbited around two stars. One can only imagine what implications this could have for the early history of the Solar System and how it might have affected planetary formation. But that will be the subject of future studies, no doubt!
The Victor M. Blanco telescope at Cerro Tololo Interamerican Observatory (CTIO) in the Chilean Andes. Credit: Berkeley Lab
Since the early 20th century, scientists and physicists have been burdened with explaining how and why the Universe appears to be expanding at an accelerating rate. For decades, the most widely accepted explanation is that the cosmos is permeated by a mysterious force known as “dark energy”. In addition to being responsible for cosmic acceleration, this energy is also thought to comprise 68.3% of the universe’s non-visible mass.
Much like dark matter, the existence of this invisible force is based on observable phenomena and because it happens to fit with our current models of cosmology, and not direct evidence. Instead, scientists must rely on indirect observations, watching how fast cosmic objects (specifically Type Ia supernovae) recede from us as the universe expands.
This process would be extremely tedious for scientists – like those who work for the Dark Energy Survey (DES) – were it not for the new algorithms developed collaboratively by researchers at Lawrence Berkeley National Laboratory and UC Berkeley.
“Our algorithm can classify a detection of a supernova candidate in about 0.01 seconds, whereas an experienced human scanner can take several seconds,” said Danny Goldstein, a UC Berkeley graduate student who developed the code to automate the process of supernova discovery on DES images.
Currently in its second season, the DES takes nightly pictures of the Southern Sky with DECam – a 570-megapixel camera that is mounted on the Victor M. Blanco telescope at Cerro Tololo Interamerican Observatory (CTIO) in the Chilean Andes. Every night, the camera generates between 100 Gigabytes (GB) and 1 Terabyte (TB) of imaging data, which is sent to the National Center for Supercomputing Applications (NCSA) and DOE’s Fermilab in Illinois for initial processing and archiving.
By studying Type Ia supernova, astronomers can measure dark energy and the expansion of the universe. Credit: NASA/CXC/M. Weiss
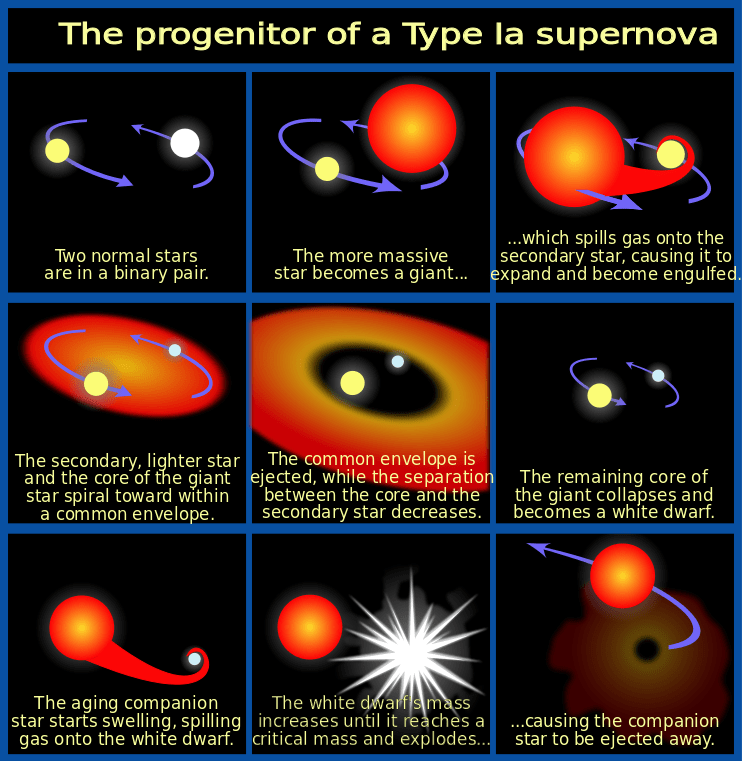
Object recognition programs developed at the National Energy Research Scientific Computing Center (NERSC) and implemented at NCSA then comb through the images in search of possible detections of Type Ia supernovae. These powerful explosions occur in binary star systems where one star is a white dwarf, which accretes material from a companion star until it reaches a critical mass and explodes in a Type Ia supernova.
“These explosions are remarkable because they can be used as cosmic distance indicators to within 3-10 percent accuracy,” says Goldstein.
Distance is important because the further away an object is located in space, the further back in time it is. By tracking Type Ia supernovae at different distances, researchers can measure cosmic expansion throughout the universe’s history. This allows them to put constraints on how fast the universe is expanding and maybe even provide other clues about the nature of dark energy.
“Scientifically, it’s a really exciting time because several groups around the world are trying to precisely measure Type Ia supernovae in order to constrain and understand the dark energy that is driving the accelerated expansion of the universe,” says Goldstein, who is also a student researcher in Berkeley Lab’s Computational Cosmology Center (C3).
Goldstein’s new code uses machine learning techniques to vet detections of supernova candidates. Credit: Danny Goldstein, UC Berkeley/Berkeley Lab)
The DES begins its search for Type Ia explosions by uncovering changes in the night sky, which is where the image subtraction pipeline developed and implemented by researchers in the DES supernova working group comes in. The pipeline subtracts images that contain known cosmic objects from new images that are exposed nightly at CTIO.
Each night, the pipeline produces between 10,000 and a few hundred thousand detections of supernova candidates that need to be validated.
“Historically, trained astronomers would sit at the computer for hours, look at these dots, and offer opinions about whether they had the characteristics of a supernova, or whether they were caused by spurious effects that masquerade as supernovae in the data. This process seems straightforward until you realize that the number of candidates that need to be classified each night is prohibitively large and only one in a few hundred is a real supernova of any type,” says Goldstein. “This process is extremely tedious and time-intensive. It also puts a lot of pressure on the supernova working group to process and scan data fast, which is hard work.”
To simplify the task of vetting candidates, Goldstein developed a code that uses the machine learning technique “Random Forest” to vet detections of supernova candidates automatically and in real-time to optimize them for the DES. The technique employs an ensemble of decision trees to automatically ask the types of questions that astronomers would typically consider when classifying supernova candidates.
Evolution of a Type Ia supernova. Credit: NASA/ESA/A. Feild
At the end of the process, each detection of a candidate is given a score based on the fraction of decision trees that considered it to have the characteristics of a detection of a supernova. The closer the classification score is to one, the stronger the candidate. Goldstein notes that in preliminary tests, the classification pipeline achieved 96 percent overall accuracy.
“When you do subtraction alone you get far too many ‘false-positives’ — instrumental or software artifacts that show up as potential supernova candidates — for humans to sift through,” says Rollin Thomas, of Berkeley Lab’s C3, who was Goldstein’s collaborator.
He notes that with the classifier, researchers can quickly and accurately strain out the artifacts from supernova candidates. “This means that instead of having 20 scientists from the supernova working group continually sift through thousands of candidates every night, you can just appoint one person to look at maybe few hundred strong candidates,” says Thomas. “This significantly speeds up our workflow and allows us to identify supernovae in real-time, which is crucial for conducting follow up observations.”
“Using about 60 cores on a supercomputer we can classify 200,000 detections in about 20 minutes, including time for database interaction and feature extraction.” says Goldstein.
Goldstein and Thomas note that the next step in this work is to add a second-level of machine learning to the pipeline to improve the classification accuracy. This extra layer would take into account how the object was classified in previous observations as it determines the probability that the candidate is “real.” The researchers and their colleagues are currently working on different approaches to achieve this capability.