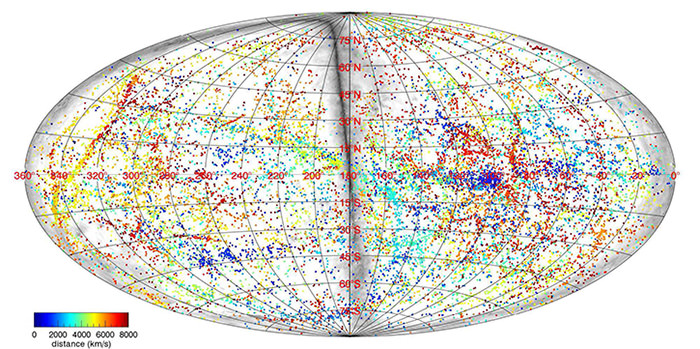
Ever since Galileo pointed his telescope at Jupiter and saw moons in orbit around that planet, we began to realize we don’t occupy a central, important place in the Universe. In 2013, a study showed that we may be further out in the boondocks than we imagined. Now, a new study confirms it: we live in a void in the filamental structure of the Universe, a void that is bigger than we thought.
In 2013, a study by University of Wisconsin–Madison astronomer Amy Barger and her student Ryan Keenan showed that our Milky Way galaxy is situated in a large void in the cosmic structure. The void contains far fewer galaxies, stars, and planets than we thought. Now, a new study from University of Wisconsin student Ben Hoscheit confirms it, and at the same time eases some of the tension between different measurements of the Hubble Constant.
The void has a name; it’s called the KBC void for Keenan, Barger and the University of Hawaii’s Lennox Cowie. With a radius of about 1 billion light years, the KBC void is seven times larger than the average void, and it is the largest void we know of.
The large-scale structure of the Universe consists of filaments and clusters of normal matter separated by voids, where there is very little matter. It’s been described as “Swiss cheese-like.” The filaments themselves are made up of galaxy clusters and super-clusters, which are themselves made up of stars, gas, dust and planets. Finding out that we live in a void is interesting on its own, but its the implications it has for Hubble’s Constant that are even more interesting.
Hubble’s Constant is the rate at which objects move away from each other due to the expansion of the Universe. Dr. Brian Cox explains it in this short video.
The problem with Hubble’s Constant, is that you get a different result depending on how you measure it. Obviously, this is a problem. “No matter what technique you use, you should get the same value for the expansion rate of the universe today,” explains Ben Hoscheit, the Wisconsin student who presented his analysis of the KBC void on June 6th at a meeting of the American Astronomical Society. “Fortunately, living in a void helps resolve this tension.”
There are a couple ways of measuring the expansion rate of the Universe, known as Hubble’s Constant. One way is to use what are known as “standard candles.” Supernovae are used as standard candles because their luminosity is so well-understood. By measuring their luminosity, we can determine how far away the galaxy they reside in is.
Another way is by measuring the CMB, the Cosmic Microwave Background. The CMB is the left over energy imprint from the Big Bang, and studying it tells us the state of expansion in the Universe.
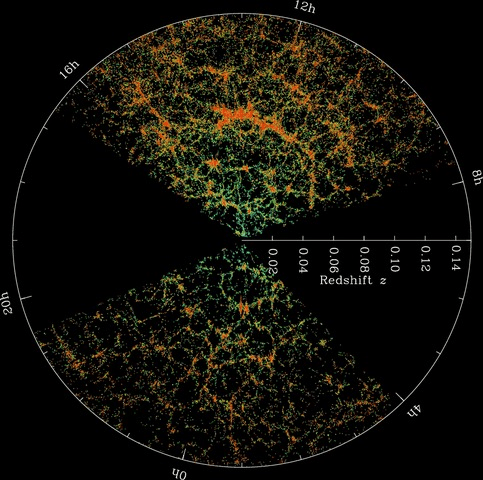
The two methods can be compared. The standard candle approach measures more local distances, while the CMB approach measures large-scale distances. So how does living in a void help resolve the two?
Measurements from inside a void will be affected by the much larger amount of matter outside the void. The gravitational pull of all that matter will affect the measurements taken with the standard candle method. But that same matter, and its gravitational pull, will have no effect on the CMB method of measurement.
“One always wants to find consistency, or else there is a problem somewhere that needs to be resolved.” – Amy Barger, University of Hawaii, Dept. of Physics and Astronomy
Hoscheit’s new analysis, according to Barger, the author of the 2013 study, shows that Keenan’s first estimations of the KBC void, which is shaped like a sphere with a shell of increasing thickness made up of galaxies, stars and other matter, are not ruled out by other observational constraints.
“It is often really hard to find consistent solutions between many different observations,” says Barger, an observational cosmologist who also holds an affiliate graduate appointment at the University of Hawaii’s Department of Physics and Astronomy. “What Ben has shown is that the density profile that Keenan measured is consistent with cosmological observables. One always wants to find consistency, or else there is a problem somewhere that needs to be resolved.”