
[/caption]
Last week’s AWAT Why Water? took the approach of acknowledging that while numerous solvents are available to support alien biochemistries, water is very likely to be the most common biological solvent out there – just on the basis of its sheer abundance. It also has useful chemical features that would be advantageous to alien biochemistries – particularly where its liquid phase occurs in a warmer temperature zone than any other solvent.
We can constrain the number of possible solutes likely to engage in biochemical activity by assuming that life (particularly complex and potentially intelligent life) will need structural components that are chemically stable in solution and can sustain their structural integrity in the face of minor environmental variations, such as changes in temperature, pressure and acidity.
Although DNA is often discussed as a core component of life on Earth, it is conceivable that a self-replicating biochemistry came later. The molecular machinery that supports the breakdown of carbohydrates uses relatively uncomplicated carboxylic acids and phospholipid membranes – although the whole process today is facilitated by complex proteins, which are unlikely to have arisen spontaneously. A current debate exists about whether life originated as replication or metabolism – or whether the two systems arose seperately before joining together in a symbiotic alliance.
In any case, although a variety of small scale biochemistries, with or without carbon, may be possible – it seems likely that the structure of organisms of any substantial size will need to be built using polymers – which are large molecular structures, built up from the joining together of smaller units.
On Earth, we have proteins built from amino acids, DNA built from nucleotides and deoxyribose sugars – as well as various polysaccharides (for example cellulose or glycogen) built from simple sugars. With only a microscopic biochemical machinery capable of building these small units and then linking them together – you can build organisms on the scale of blue whales.

Carbon is extremely versatile at linking together diverse elements – able to form more compounds than any other element we have so far observed. Also, it is more universally abundant that the next polymeric contender, silicon – and it’s worth considering that on Earth, although silicon is atypically 900 times more abundant than carbon – but still ends up having a minimal role in Earth biochemistry. Boron is another elemental candidate, also very good at building polymers, but Boron is a relatively rare element in the universe.
On this basis, it does seem reasonable to assume that if we ever meet a macroscopic alien life form – with a structural integrity sufficient to enable us to shake hands – it will most likely have a primarily carbon-based structure.
However, in this scenario you are likely to be met with a puzzled query as to why you seek tactile engagement between your respective motile-sensory appendages. It may be more appropriate to offer to replenish your new alien friend’s solvents with some heated water mixed with a nitrogen, oxygen, carbon alkaloid – something we call coffee.
Further Reading:
Meadows et al The Search for Habitable Environments and Life in the Universe.
Wikipedia Hypothetical Types of Biochemistry.
“it is worth noting that carbon is not intrinsic to the nucleotides (composed of hydrogen, oxygen and nitrogen) that form the coding units of DNA – nor is it part of vital energy-transferring molecules like adenosine triphosphate (which has a similar chemistry to nucleotides with three phosphate groups attached).”
The formula of adenosine is C10-H13-N5-O4, it is composed primarily of carbon atoms! Similarly all of the other nucleotides are carbon based. I do not understand your logic in saying that carbon is not intrinsic to nucleotides, and that life could have started without carbon. Without carbon these molecules simply cannot exist!
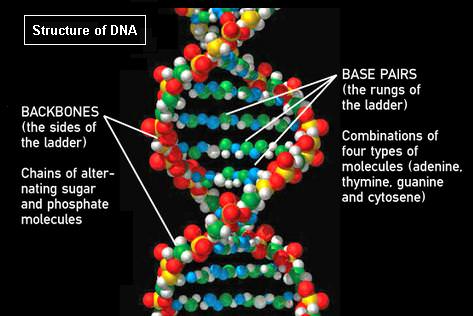
Perhaps you have been misled by the image of the structure of DNA used for this article. It confusingly shows base pairs as long thin chains of N, O, and H atoms.
Here are images that accurately shows the position of all the atoms in DNA. These images were taken from Protein Data Bank file 3BSE.
http://i53.tinypic.com/23wp4wp.jpg
http://i55.tinypic.com/121g22g.png
Clearly lots of carbon is involved!
[Added in posting (hey, I remembered to update first!): Jlazor has noted the “intrinsic” carbon mystery before me.]
One of the reasons why carbon is so versatile is that it is able to configure its bonds in various ways, more than other molecules. This is actually nicely shown by carbon on its lonesome (or with hydrogen), making everything from hydrocarbon chains to graphite sheets over diamond structures to fullerenes.
I’m not sure what is meant by “intrinsic here”. But nucleotides, or better, the core nucleosides, consist of a sugar (ribose or deoxyribose), and a nucleobase (purine or pyrimidine), both of which are carbon compounds. Sugars are rings stitched with oxygen (typically mostly C in organic sugars) while nucleobases are rings stitched with nitrogen (typically a little less N than C in organic bases).
These CHON compounds (a subset of the basic CHNOPS compounds that form cells) are interesting probiotic members. Modern analysis of the Murchison meteorite, or lab synthesis from HCN constituents, shows how linear and ringed CHON compounds builds along two pathways. The upshot is that you can get amino acids and nucleobases probiotically.
But sugars don’t arrive that easily! IIRC, but I have to check this, there is now found a natural synthesis pathway for some nucleosides, which involves phosphates. I.e. it would be a natural way that coupled P to CHON.
What about S then? Well, it seems to invade the CHON set of hydrocarbons in Murchison by substitution afterwards, i.e. its CHONS set mirrors its CHON set. (P is relatively scarce and/or tied up in minerals, which may explain its initial absence.)
My own preference at the moment would be the later, actually based on the results above. The reference on possible nucleoside pathways gives a pathway that is not mirrored in modern cell metabolism, as I remember it. I.e. these pathways were likely established after an RNA world (“genetic”) takeover and control of probiotic metabolism.
“probiotic metabolism” – protobiotic metabolism, rather.
So are you saying that Carbon is not essential to the coding of DNA as a base scaffold for chemistry, that silicon (as an example) could theoretically fulfill the role of carbon in organic chemistry?
Its my impression that carbon atoms in combination with Hydrogen, Oxygen and other elements create the base elements in Organic chemistry that DNA and RNA utilize. Its not ‘intrinsic’ but does form the base structural chains that form all other organic compounds including nucleotides. (this is not well explained in the article)
i.e “A nucleotide is composed of a nucleobase (nitrogenous base), a five-carbon sugar (either ribose or 2′-deoxyribose), and one to three phosphate groups.”
http://en.wikipedia.org/wiki/Nucleotide
Also:
“Carbon has the ability to form very long chains of interconnecting C-C bonds. This property is called catenation. Carbon-carbon bonds are strong, and stable. This property allows carbon to form an almost infinite number of compounds; in fact, there are more known carbon-containing compounds than all the compounds of the other chemical elements combined except those of hydrogen (because almost all organic compounds contain hydrogen too).”
http://en.wikipedia.org/wiki/Carbon
Definitional issues may or may not clarify how systems work. I like to draw a sword for the evolutionary understanding of life since it is, after all, a biological phenomena.
Then life is what partakes in the evolutionary process, “a process that results in heritable changes in a population spread over many generations”.
Trivially “replicator molecules” aren’t life, they can’t change by evolutionary processes.*
Similarly trivially “metabolic molecules” aren’t life, their hereditary information isn’t learned from the environment but distributed over the environment.**
It is precisely when a genetic process is established that evolution is established in full, and that genetic process in turn relies on metabolic processes for turnaround. This is why the symbiotic alliance is seen.
[It doesn’t explain why it started though, only why it continued up to the point cells were established, it enabled better adaptation. Free cells on the other hand would make a snack out of sundry predecessors, so made an irreversible change on the evolving biosphere.]
* Now you may think that this means replicators are robust. Rather, Shostak’s ideas of replicating ribozymes need encapsulating cell walls in order not to replicate any and all RNA polymers around and dilute itself to oblivion.
The problem with replicator molecules is that they are “just so” and so fragile, while replicating systems (like RNA-enzyme systems) are robust under adaptive change.
** This can of course be defined away, so heritability means something other and more general than the rather idiosyncratic form it takes today. But this fuzzified gray area points out how we are discussing a transition here – it is supposed to be fuzzy!
Ahem. I may have confused specific and non-specific replicators here. (“Specific” replicators are the usual self-replicators traditionally considered.) They are both fragile, the first because it isn’t adaptive which was my original point, the later for the reason I mentioned.
But – and this is where it comes out I really considered strict self-replicators earlier – the later is evolvable, Shostak’s protocells are life if he puts replicators (say, RNA replicase which can replicate itself after two rounds of replicating mirror strands) instead of strict self-replicators there. Or, as we discussed last time on water, if natural PCR cycles replicates some of the single strands by way of double strand formation and later breakup.)
“replicator molecules … can’t change by evolutionary processes”
I can’t see why. As long as mistakes in the replication are possible there is evolution. Or is that too simple a view?
No, that is it.
It is just that many RNA self-replicators seem incapable of mistakes, as far as I know. For example, there is a set up with two ingredients that catalyzes each other’s bonding out of two simpler ingredients (A+B -(C)-> D, E+F -(D)-> C). You can vary them I think, but they can just do that one specific function. Perhaps they can show evolution in that system, using other raw material or so.
Now, non-specific RNA replicase exist as several alleles so it can evolve. Being part of a cell machinery is of course what gives that, but there doesn’t seem to be any barrier for replicase to evolve on its lonesome by slight modifications.
But honestly, I’m looking at my comment today, and it seems a rather artificial separation. Maybe the biological definition wasn’t all that helpful as I first thought. Still, it may point out a potential deterministic, bottleneck, difficulty for evolution and shore up the reasons for the subsequent, as Steve says symbiotic relationship between genetic and metabolic systems. But not as is, as almost everywhere else data is needed. My bad.
The geometry of the carbon p orbitals and their energy is unique. They form a tetrahedron and span 3-space and have moderate energy. Boron and nitrogen have 5 and 3 orbitals available (and in a way are dual to each other), but span only a plane. The bonds are hard, particularly with nitrogen.
The fact there are 4 avilable orbitals in space (not just a plane) means that for a range of chemical energies you can have a huge array of shapes.
LC
Sorry Jlazor and others, you are right that I was mistaken and I have amended the text. I am interested in how carbohydrate might arise spontaneously (CO2 + H20 – but seems to require energy input, e.g. photosynthesis) to provide a metabolic substrate. Thought I was on to something there, but no…
That is not a DNA structure in the drawing. Why would one put such an effort into drawing a complicated structure with little in common with a real nucleic acid?
If it’s helpful – this was a diagram NASA was running with to support their dialogue about the arsenic bacteria (where arsenic allegedly replaced phosphate in the ‘backbone’). Otherwise not sure what the problem is – and not sure that there was that much effort involved 🙂
Yeah, that is quite a pickle.
As I understand it, there are common pathways for building linear and ringed carbohydrates and carbonitrogens in space (dust, asteroids) and in atmospheres (Titan). Either by reactions with fancy names like Strecker reactions and more, and/or UV-mediation.
On Earth’s surface and crust these things go on to build linear chains and amino acids, rings not so much. This is what you can see around hydrothermal vents by Fischer-Tropsch processes and ZnS/MnS UV photosynthesis. Both of these need minerals and CO2/water, the later at CO2 pressures that we don’t see today (10 bar or upwards).
[Actually, as I understand it Fischer-Tropsch as such need previous catalysis of CO2 to CO on the right minerals as the gases goes up the hydrothermal vent. Vent-deposited ZnS/MnS doesn’t need that but makes formic acid directly from CO2 + H2O, instead it needs near surface conditions for UV. (It can also use radioactivity, but that is even rarer.)
Both of those should have been active on primordial Earth, and of those the ZnS/MnS deposits observed could easily have been the largest producer of organics on Earth.]
The nucleoside pathway I mentioned earlier makes sugars and nucleobases by bypassing the stepwise “to sugar to nucleobase” synthesis of modern cells.
“Pyrimidine ribonucleosides and their respective nucleotides have been prebiotically synthesised by a sequence of reactions which by-pass the free sugars, and are assembled in a stepwise fashion by going against the dogma that nitrogenous and oxygenous chemistries should be avoided. In a series of publications, The Sutherland Group at the School of Chemistry, University of Manchester have demonstrated high yielding routes to cytidine and uridine ribonucleotides built from small 2 and 3 carbon fragments such as glycolaldehyde, glyceraldehyde or glyceraldehyde-3-phosphate, cyanamide and cyanoacetylene.”
What is required is a previous enantiomer excess, so carbohydrates by that route is still tied up to some preexisting protein system is the environment. (Which protein systems would have been enantiomeric to be able to build heteropolymers.) Also concentrations of phosphates, which both participate and enhance rates.
Enantiomer excess as expressed in proteins in turn commonly relies on some preexisting RNA world system. So we have a chicken-and-egg problem here.
I’ve seen pathways that solves such problems I believe, IIRC there are synthesis pathways that builds protein heteropolymers by repeated dry-wet cycles (think tidal beach) and selection for longer chains. So it could happen without preexisting RNA systems.
And now all you need is a biggish tidal driver moon, or a slowly tidal locking exoplanet in the habitable zone of an M star…
Ah, you could also get by with surface pools or volcanic hot springs cycling surfaces through dry-wet conditions. All habitable planets may apply for that pathway then.
To tie my comments together and provide a missing reference:
My own preference right now for the order of genetic and metabolic symbiosis is probiotic metabolism first. This is based on the result mentioned on Why Water? AMAT, of natural (enthalpic) enzymes selected out as Earth’s temperature went down.
A preexisting drive for network building in a robustly productive setting would have selected out a natural symmetry breaking to some set of productive enantiomers adapted to the local environment. (I think. What do you think?)
That would bypass the need for an excruciatingly slow protein building scenario I painted in my previous comment. Then feasibly nucleobases could have been at at first parasitic free riders on a simple sugar metabolism (or perhaps bona fide functional, as in ATP/NAD), later adapted to symbionts as they enhanced evolution. (But of course at the core still “selfish” genes, as per Dawkins.)
You don’t see it from the figure above, but the Krebs metabolites could have simply been a result of two ‘half Krebs’ forked non-cyclic pathways that were used for other stuff (including nucleobases eventually) and only closed in later cells.
As the availability of natural enzymes became insufficient or new pathways were added, an RNA world enhancing reactions by coupling to amino acid dimers would start the evolution of proteins.
The recent (2009) Murchison CHONS results, using high resolution Fourier transform ion cyclotron resonance/mass spectrometry (FTICR/MS) (and several solvents) to extract some > 30 000 (!) different signals. (Or some > 100 000 signals at SNR ~ 1.)
I think that I learn more reading the articles and comments on this site than I ever did in state funded science classes… Thanks folks.